Une des questions récurrentes que l’on m’adresse au sujet de l’analyse de logs, que ce soit lors de conférences ou de formations, c’est la manière de dissocier les « vrais » et les « faux » Googlebots. Puisque le sujet n’est pas si trivial, voilà donc un article pour vous expliquer comment vérifier l’intégrité de vos données, avec un petit cadeau 😉
Un peu de contexte
Les logs serveur sont une mine d’information pour les référenceurs. Ils permettent en effet de trouver rapidement des pistes d’amélioration, tout en fournissant un moyen fiable de s’assurer de la bonne santé d’un site.
Pour en savoir plus, je vous invite par exemple à consulter les slides de ma conférence au SEO Campus de Nantes en février dernier.
Mais pour réaliser des analyses fiables, il faut s’assurer que les données que l’on utilise le sont aussi.
Un des problèmes récurrents, c’est la présence dans les logs serveurs de données correspondant à de « faux » Googlebots : des robots ou des utilisateurs qui cherchent à se faire passer pour Google.
En effet, il n’est pas bien compliqué de modifier son User-Agent (en quelque sorte votre carte d’identité que vous présentez à chaque site web où vous vous rendez) pour utiliser celui de Googlebot. Jetez par exemple un oeil à cette extension pour Google Chrome.
Qu’il s’agisse donc d’outils de monitoring, de concurrents ou de robots malicieux, n’importe qui peut vous faire croire qu’il est Googlebot.
La méthode Google
Heureusement, Google (tout comme les autres moteurs de recherche d’ailleurs) fournit une méthode qui permet de vérifier qu’un visiteur sur votre site provient bien de ses serveurs. Décrite ici, cette méthode consiste en fait à comparer les résultats d’une double résolution DNS.
Cadeau !
Nous avons décidé de mettre à disposition de la communauté un petit script PHP développé en interne, qui permet d’effectuer la vérification proposée par Google.
Découvez-le sur GitHub !
Le principe est simple : vous rentrez une liste d’adresses IP à vérifier, et pour chacune d’entre elles, l’outil va effectuer une résolution DNS inversée, c’est à dire qu’il va identifier le nom de domaine associé à cette IP.
Ensuite, il va faire l’inverse : vérifier l’IP associée au nom de domaine.
Si cette seconde IP est identique à la première, c’est qu’elle est légitime.
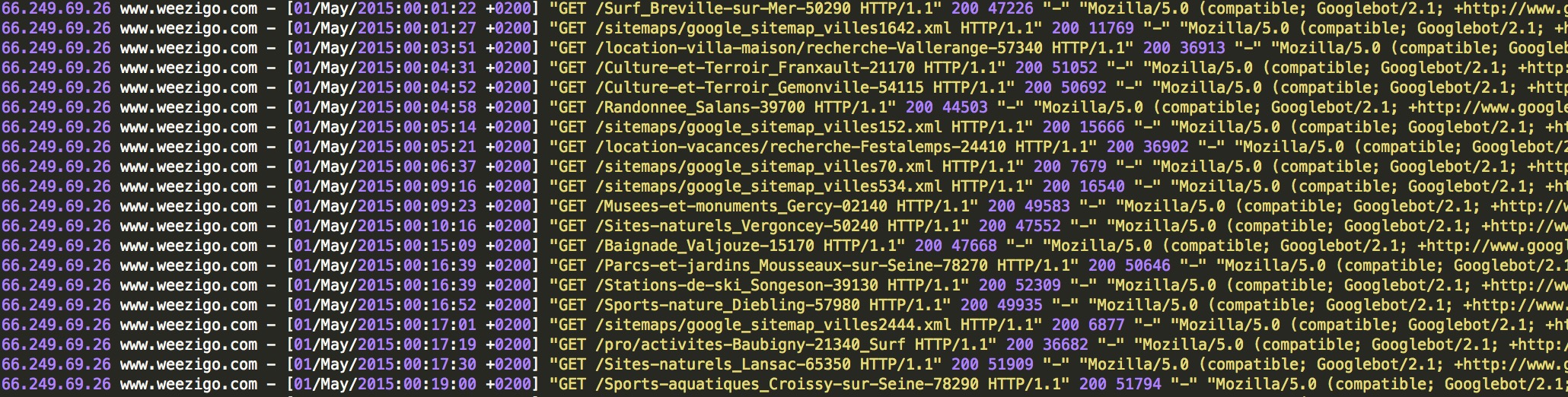
Voici par exemple le résultat du test de 2 adresses de Googlebot :

L’outil est simpliste mais fonctionnel. N’hésitez pas à contribuer sur Github pour l’améliorer si vous le souhaitez.
Aller plus loin
Construire une whitelist
Utiliser cet outil pour chaque analyse est fastidieux. Pour gagner du temps, construisez votre propre white list d’IP vérifiées. Vous n’aurez ainsi qu’à vérifier les nouvelles IP rencontrées.
Bloquer les robots malicieux
Lorsque vous identifiez un faux Googlebot qui crawle votre site de manière récurrente, la bonne pratique est de bloquer l’IP correspondante pour lui interdire purement et simplement l’accès à vos pages.
Si vous souhaitez par exemple bloquer l’IP 255.0.0.0 sur un serveur Apache, ajoutez ces lignes à votre vhost ou votre fichier .htaccess :
order allow,deny
deny from 255.0.0.0
allow from all
Et les autres moteurs ?
La méthode fonctionne avec la plupart des moteurs et autres services qui crawlent le web, comme Majestic par exemple. Certains vont plus loin, comme Bing qui propose son propre outil de vérification, mais limité à une seule IP à la fois.
Dans tous les cas, n’hésitez pas à essayer cette méthode ! возьму деньги в долг по паспорту

Je ne sais pas si c’est moi qui suit complètement à côté de la plaque mais je ne comprends pas l’importance donnée à l’analyse de logs pour le SEO. Pour des gros sites ok, mais je trouve qu’il y a déjà suffisamment de données à analyser à côté. Non ?
Effectivement, l’analyse de logs est un sujet à la mode dans le microcosme SEO. Mais ça n’est pas pour autant une réelle nouveauté. Il s’agit d’un outil indispensable pour les sites à fort volume de pages, en effet, mais il a également un intérêt pour les sites de taille plus modeste. C’est en fait le seul moyen de voir certaines choses, et notamment d’analyser le comportement de Googlebot sur un site : consulte-t-il les bonnes pages ? voit-il des pages qui sont en dehors de l’arborescence ? rencontre-t-il des erreurs ? …
Cela étant, cet outil supplémentaire nécessite effectivement du temps supplémentaire à y consacrer. Mon conseil à ce sujet est bien souvent de traiter d’abord les problèmes que l’on aura trouvé par ailleurs, avant de s’intéresser aux logs.
Hello 😉
Oui, tu as bien raison d’insister sur cette dissociation. Mais mon avis diffère sur la finalité. Selon les sites, les fakes peuvent être très nombreux, et biaiser complètement les stats, ça c’est vrai. Certains outils « premium » que je ne citerai pas, font totalement l’impasse sur le reverse DNS… Mais quelque part, cela peut se comprendre. La résolution DNS demande de la ressource, et surtout du temps 😉 Donc la résolution DNS à la volée pour les outils orientés monitoring temps réel c’est plus compliqué. Mais il y a des parades que très peu utilisent : mettre en cache les différentes IPs déjà résolues, pour ne pas avoir a systématiquement rechecker les IP déjà traitées.
Pour les outils de reverse DNS. Je n’ai pas testé celui déposé sur Github. Cela dit, il en existait déjà un : http://www.infobyip.com/ipbulklookup.php
Cela dit, a force de faire des analyses de logs, j’en suis venu à appliquer une solution infiniement plus simple et rapide : je dégage toutes les IP qui ne sont pas en 66.249.*.*. Ouai c’est un peu bourrin, mais faut se rendre à l’évidence : 99,5% du temps toutes les vraies IP de Google sont avec le bloc 66.249, tant pis pour les 0.5% restant. Le reverse DNS n’est indispensable que pour le cloaking. Enfin c’est mon avis 😉
Bonjour Aurélien 🙂
En effet, se construire une « whitelist » est important, car ça permet de gagner du temps et de ne devoir analyser que les nouvelles IP. Ca aura d’autant plus d’intérêt que Google utilise de plus en plus d’IP hors du bloc 66.249.*.*, et qu’il devient donc vite difficile d’y voir clair.
Merci en tout cas de partager ton point de vue.
Pas mal le coup de la double vérification, c’est une bonne idée. J’ai déjà eu des galères avec des logs qui avaient étés complétement spammés et à l’époque cela aurait été bien pratique pour voir ce qui est légitime ou pas …